~/sixdegree-ai/boundary
$ cat README.md
boundary
Find where your LLM's context breaks
● activePython · MIT
Boundary pushes LLMs to the edges of their context capabilities so you don't discover the limits in production. It runs reproducible tests against LLM providers to measure how models behave under real-world agent conditions. Each test is self-contained with its own data, runner, and analysis. Currently includes a tool-overload test with 150 tool definitions across 16 services including GitHub, GitLab, Jira, Kubernetes, AWS, Datadog, Grafana, Terraform Cloud, and more.
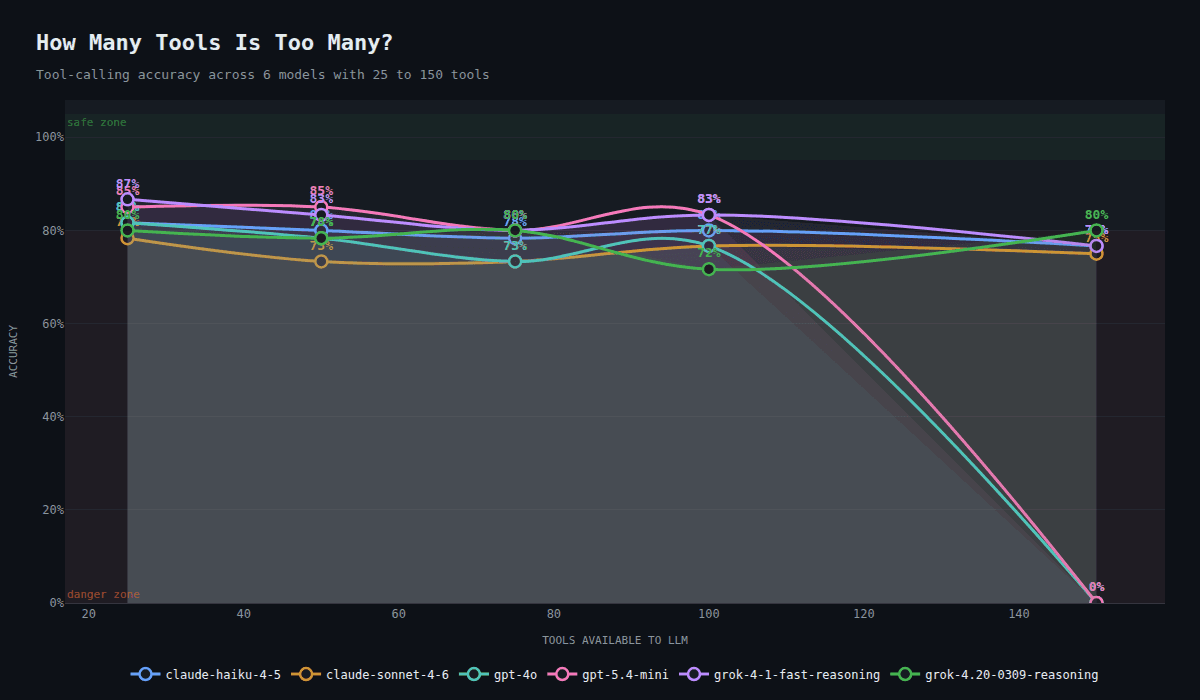
Accuracy degrades as toolset size increases
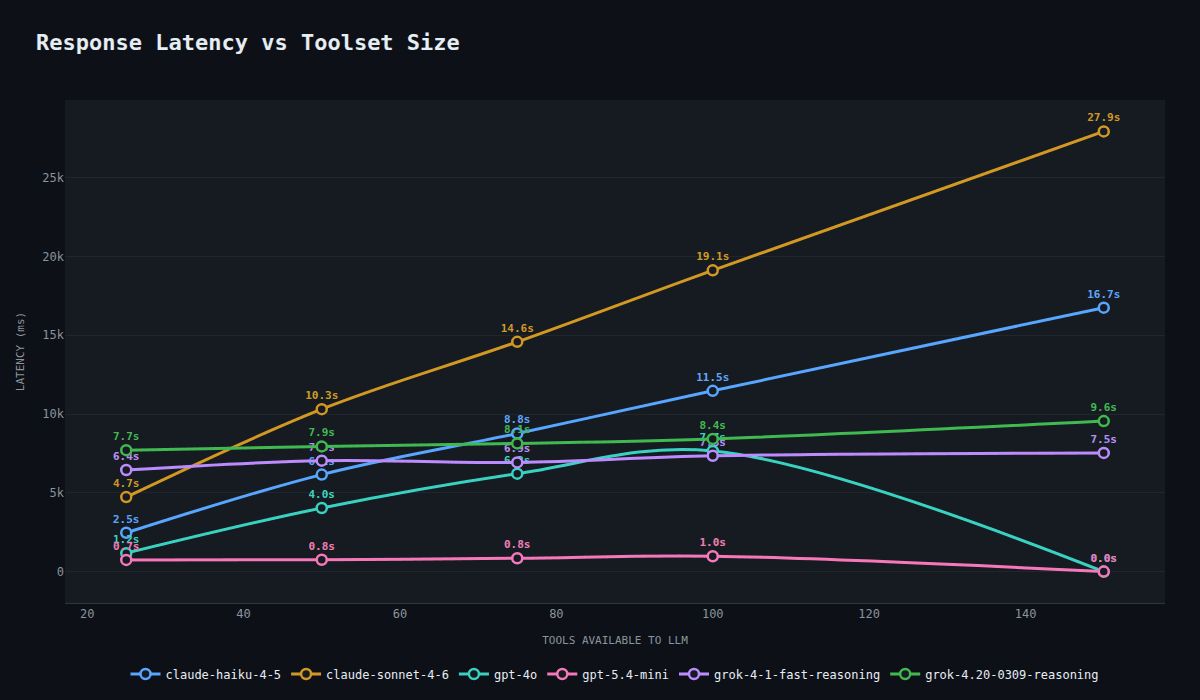
Latency scaling varies wildly by provider

Token usage scales linearly with tool count
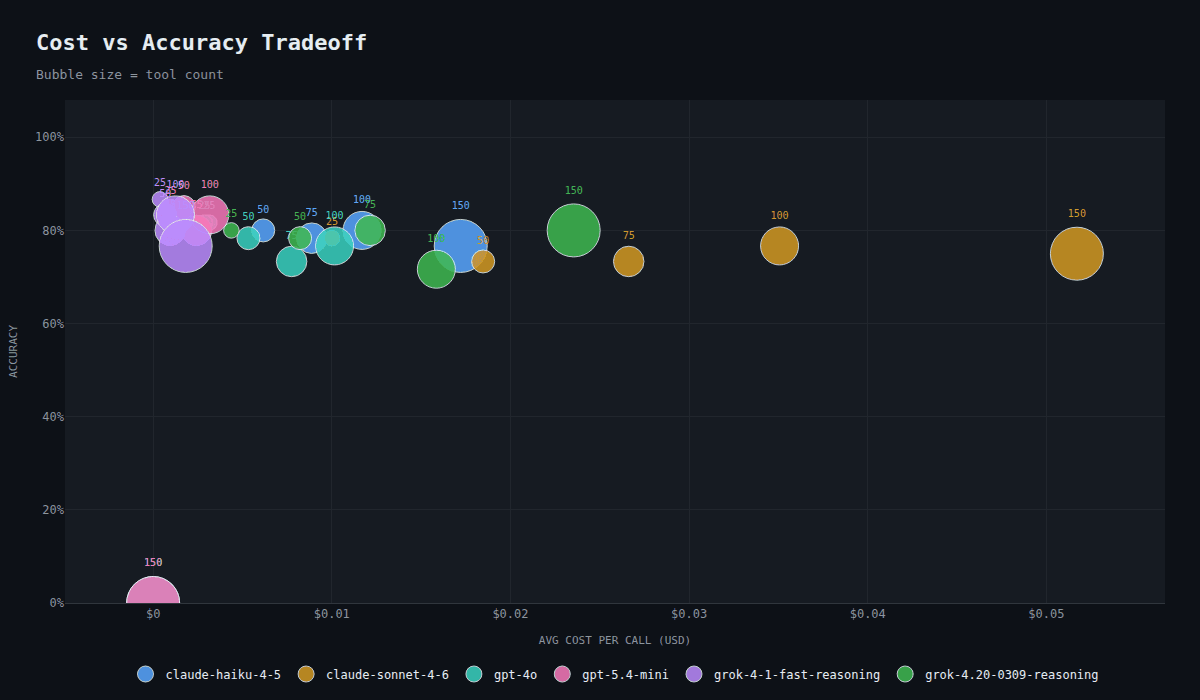
Cost vs accuracy tradeoff across models
$ boundary --features
▸Tool selection accuracy testing at increasing toolset sizes (25 to 150 tools)
▸Cross-service confusion detection (GitHub vs GitLab, Kubernetes vs Docker)
▸Multi-provider support: Anthropic, OpenAI, Google, xAI
▸Interactive Plotly charts for analysis and comparison
▸Plugin architecture: contribute your own tests
$ boundary --quickstart
# Clone the repo
$ git clone https://github.com/sixdegree-ai/boundary.git
$ cd boundary
# Create a .env file with your API keys
cat > .env << 'EOF'
ANTHROPIC_API_KEY=sk-...
OPENAI_API_KEY=sk-...
GOOGLE_API_KEY=...
XAI_API_KEY=xai-...
EOF
# List available tests
$ uv run boundary list-tests
# Run the tool-overload test against Claude Sonnet
$ uv run boundary tool-overload run -p claude-sonnet
# Run against multiple models
$ uv run boundary tool-overload run -p claude-sonnet -p gpt-4o -p gemini-flash
# Analyze results and generate charts
$ uv run boundary tool-overload analyze
$ boundary --related
$ echo $TAGS
[AI][LLM][Tool-Calling][Benchmarks][MCP]