Why Live Knowledge Graphs Are the Missing Context Layer for Safe Agentic AI in 2026
Customer support agents fail in production because they lack live context: who owns the account, what they use, what's at risk. Live knowledge graphs fix the substrate RAG and raw MCP can't touch.

Multi-agent AI is no longer a research curiosity. In 2026, coordinated agent systems are being deployed across support, ops, and engineering at real companies. Orchestrated workflows, long-running goal-oriented agents, and "agent teams" that hand off context between specialized subagents. These aren't demos anymore. They're moving into production.
And yet, the failure rate is embarrassing.
Not because the models are bad. Not because the tools are missing. The agents that are failing have access to strong models, retrieval pipelines, and growing catalogs of MCP-connected services. They still hallucinate ownership. They still get the scope of impact wrong. They over-privilege their own tool access, make decisions based on stale org structures, and collapse under the weight of maintaining coherent context across more than a few steps.
The problem isn't capability. It's context. Specifically, it's the absence of a live, structured, auto-discovered model of how the organization actually works. Not a document. Not a set of embeddings. A graph that reflects real relationships between customers, accounts, products, owners, and workflows, updated continuously, and queryable at inference time.
That's the missing layer. Not a better model, not more prompts, not another retrieval pass. A live knowledge graph that agents can reason over with the same confidence a senior support lead or veteran account manager reasons over institutional memory they actually trust.
The 2026 Agentic Landscape: Real Progress, Real Pain
The shift from single-task agents to coordinated multi-agent systems has happened faster than most people predicted. A year ago, "agentic AI" mostly meant a chatbot that could call a function. Today it means orchestrators that spawn specialized subagents, long-running pipelines that autonomously handle escalation triage or compliance review, and support agents that act on customer-facing systems through the systems of record, without a human in the loop on every step.
Gartner recently defined the context layer as foundational for AI success, breaking it into three components: semantics (what things mean in the context of your organization), operational state (current, live awareness of what's true right now), and provenance (the ability to trace where an answer came from and whether that logic is still valid). a16z arrived at a similar framing around the same time, arguing that agents fail not because LLMs are incapable, but because the structured context they need doesn't exist in any accessible form. It's a useful framework, and a live knowledge graph addresses all three, though not in the way you might expect. Operational state is continuous sync from systems of record. Provenance is queryable graph lineage. On semantics, the approach is different: rather than inferring meaning probabilistically, the graph encodes it structurally.
Semantic approaches are probabilistic by nature. Meaning is inferred, similarity is approximated, interpretation varies by context. A live graph doesn't infer ownership. It records it as a first-class relationship. A dependency isn't a cosine distance; it's an edge. That's not a knock on semantics as a tool; it's a recognition that for the questions agents need to answer at runtime, probability isn't good enough. You need structure.
The excitement is warranted. The failure modes are also real.
Three categories of failure show up repeatedly across teams building in this space:
Context gaps. Agents make decisions based on what they can retrieve, not what's actually true. They don't know who owns an account because that information lives in a Slack thread from six months ago. They don't know that the outage affecting one customer also touches a high-value account mid-renewal. Retrieval helps with static facts. It doesn't help with the live relational structure of an organization.
Tool overload and over-privilege. As MCP tool catalogs grow, agents increasingly select the wrong tool, sequence tools incorrectly, or invoke tools with access they shouldn't have for the task at hand. In our Boundary benchmark, tool overload began degrading agent performance well before catalogs hit 150 tools. Without rich context to guide selection, the agent is essentially guessing.
Governance blindness. There's a lot of governance conversation happening in 2026. Most of it is about policies, frameworks, and approval workflows. Governance as an organizational process sitting above the agent layer. That matters. But it's not the hard problem. The hard problem is runtime governance: what the agent can actually see, touch, and affect in the moment it's operating. You can write all the policies you want. If the agent doesn't have accurate organizational context, those policies can't be enforced. An agent that doesn't know who owns an account can't respect ownership boundaries. An agent that doesn't know what an account depends on can't scope its impact. An agent working from stale context will make confident decisions that violate constraints it doesn't know exist. The OWASP Top 10 for LLM and Generative AI Applications names Agent Goal Hijack, Tool Misuse and Exploitation, and Identity and Privilege Abuse as the leading risk categories. All of these are failures of runtime context, not failures of policy. You can't govern what you can't see.
The gap between demo and deployment has a name. It's context.
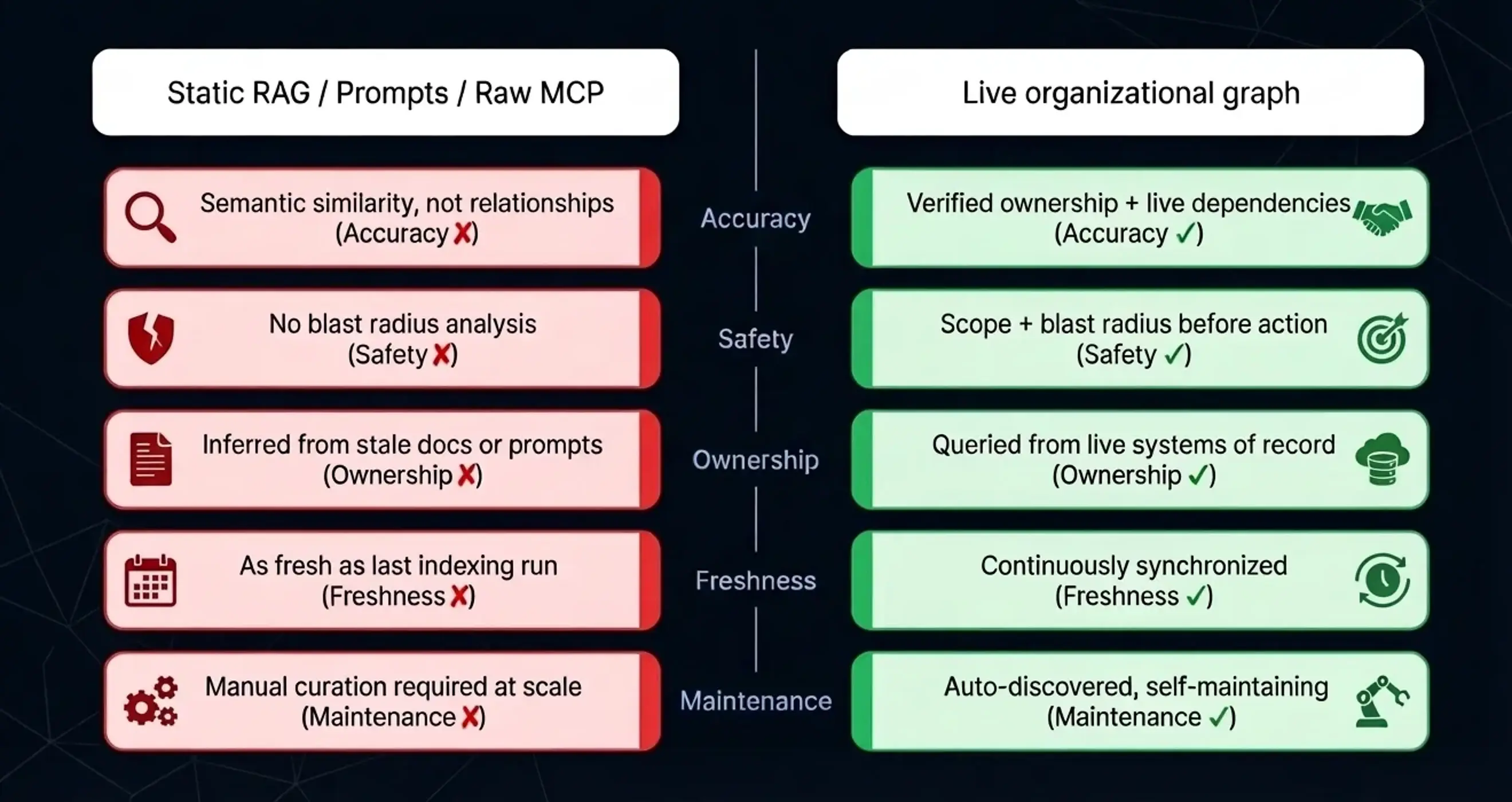
Why Static Approaches Fall Short
Most teams building agentic systems are working with some combination of prompts, RAG, and MCP tool catalogs. Each has real value. None of them solve the underlying problem.
Prompts alone hit the obvious limits fast. Token windows constrain how much context you can stuff in. Prompt-based context drifts. It reflects the moment it was written, not the current state of the organization. And there's no grounding mechanism. An agent told "the success team owns the enterprise accounts" has no way to verify that's still true today.
Traditional RAG made a lot of things better. It brought retrieval into the loop and enabled agents to work with large knowledge bases at inference time. But RAG is fundamentally optimized for documents. It answers "what does this text say" well. It answers "who owns this account right now, and what changed about it yesterday" poorly. Embeddings capture semantic similarity. They don't capture organizational relationships, dependency graphs, or temporal changes. Those are the things that determine whether an agentic decision is safe.
We explored the specific failure modes of RAG as a substrate for agentic reasoning in an earlier post. The short version: document retrieval and relationship-aware reasoning are different problems, and conflating them is where things go wrong.
Raw MCP tool-calling is powerful for integration but creates its own set of challenges at scale. Without rich context guiding tool selection, agents over-privilege. Without structured organizational knowledge informing tool sequencing, agents mis-sequence. And without real-time relationship data to scope tool access, the scope of impact of a bad decision expands. MCP is excellent infrastructure. It isn't context.
The core issue is that all three of these approaches treat context as a retrieval problem. But the hardest questions agents need to answer in production aren't retrieval questions. They're relationship questions. Who owns this? What depends on that? What changed, and what does it affect? What's the scope of impact if this goes wrong?
Answering those questions requires a different kind of structure.
Live Knowledge Graphs: What They Are and Why They Work
A live knowledge graph is a continuously updated, queryable model of how a domain actually works: its entities, relationships, and state, represented as nodes and edges rather than flat documents or disconnected data sources. In the context of customer support organizations, that means customers, accounts, products, owners, and workflows. But the pattern applies anywhere you have complex relationships that need to be reasoned over accurately at inference time.
The "live" part matters as much as the "graph" part. Traditional knowledge graphs and CMDBs are useful for what they capture, but they decay. They reflect the organization as it was when someone last manually updated them. A live knowledge graph is auto-discovered, built from systems of record like the CRM, the support platform, billing, and the product itself, and continuously synchronized. When a new account is onboarded, the graph knows. When ownership changes, the graph reflects it. When an account's products or contract change, the graph updates.
For agents, this changes what's possible in three fundamental ways.
Accurate reasoning over real relationships. An agent investigating a support escalation can trace exactly which account is affected, who owns the relationship, which products they rely on, what their contract covers, and which other accounts and teams they're tied to. Not from a prompt, not from a RAG pass over documentation, but from a queryable graph that reflects actual operational state. The difference between "the agent thinks X owns this account" and "the agent can verify X owns this account" is the difference between a recommendation and a decision you can trust.
Governance that's structural, not procedural. This is the one most teams are missing. Governance isn't something you bolt onto an agent system after the fact. It's a property of having accurate, queryable structure underneath the agent. When the graph knows who owns what, which systems are in scope, and what each account relies on and which other accounts it's tied to, the agent can enforce constraints at query time rather than relying on policies written into prompts that can drift or be overridden. Scope-of-impact analysis becomes a graph query. Least-privilege scoping becomes a graph query. Before acting on an account, the agent asks the graph: what else does this affect? Before invoking a tool, it asks: is this the right scope for this task? That's not policy enforcement. That's governance built into the reasoning layer itself.
Scalable multi-agent coordination. In multi-agent systems, the hardest problem is shared context. How do you ensure that a subagent handed a task from an orchestrator is working from the same understanding of the organization? A live graph serves as institutional memory that all agents share. Subagents can discover dependencies, validate assumptions, and hand off context with confidence they're working from the same ground truth. This is what makes long-running, goal-oriented agent pipelines actually reliable.
To make this concrete: an agent coordinating a support escalation needs to know which account is affected, who owns the relationship, which products they rely on, what their contract covers, and which other accounts and teams depend on them. With a live knowledge graph, that's a handful of graph queries. Without it, the agent is piecing together context from documentation that may be months out of date, Slack history it can't access, and tribal knowledge it doesn't have. One of these produces a reliable resolution. The other produces a hallucinated one.
From Theory to Practice: Graphs Make MCP and Agents Production-Ready
The integration point between live knowledge graphs and MCP is where a lot of the practical value surfaces.
When agents query the graph before tool selection, the tool catalog problem becomes manageable. Rather than presenting an agent with 150+ tools and hoping it picks the right one, the graph narrows the relevant tool space based on what it knows about the task context: which accounts are involved, what their dependencies are, who should be acting on them. Tool selection accuracy improves dramatically, and with it, agent reliability.
When graphs inform authorization, the over-privilege problem shrinks. The agent doesn't just know what tools are available. It knows whether invoking a given tool for a given task, against a given account, is appropriate given the organizational structure. That's not access control with extra steps. That's governance at the point where decisions actually get made.
A useful frame for assessing graph readiness for agentic workloads covers four questions:
Auto-discovery coverage. Is the graph built from live systems of record, or does it require manual maintenance? A graph that decays between updates isn't useful for production agents.
Query latency. Can the graph answer relationship queries at inference time without adding unacceptable latency to agent execution? If graph queries are too slow, agents will skip them.
Governance depth. The graph shouldn't just expose data. It should be the mechanism through which ownership, scope, and access constraints are enforced. If governance is a separate layer sitting on top of the graph, it will drift from the graph. They need to be the same thing.
Temporal accuracy. Does the graph reflect current state, or last-known state? For agents making decisions about live operations, the difference matters. Stale context produces confident decisions that violate constraints the agent doesn't know have changed.
A common objection worth addressing: "Isn't this just a CMDB?" No, for a few reasons. CMDBs are manually maintained and decay fast. They're typically asset-centric, not relationship-centric. And they're not designed for real-time inference-time querying by autonomous agents. A live knowledge graph is purpose-built for agentic workloads: auto-discovered, relationship-first, and optimized for the kinds of queries agents actually need to answer.
A second objection is starting to circulate as the market gets noisier: "A context graph is just one component of the context layer." Worth taking seriously. It's true that a graph alone (static, manually maintained, disconnected from live systems) is insufficient. But a live knowledge graph that's auto-discovered and continuously synchronized isn't a component. It's the substrate. Operational state is in the continuous sync. Provenance is in the queryable lineage. And rather than approximating semantics probabilistically, the graph encodes meaning structurally: ownership as an edge, dependency as a relationship, scope as a traversal. The warning about vendors conflating "context graph" and "context layer" is fair. The answer isn't to treat the graph as one piece of a larger manual architecture. It's to build the graph right.
What Enterprises Should Do in 2026
The organizations getting the most out of agentic AI right now are doing a few things differently.
They're starting with high-impact use cases where context failures are most costly: support escalations, account health analysis, renewal-risk analysis. And they're building context infrastructure first. The agent layer comes after, not before.
They're treating the context graph as a platform investment, not a project deliverable. A live knowledge graph that serves one agentic use case well will serve ten well. The cost of building it amortizes across every agent workflow the organization runs.
They're choosing auto-discovery over manual ontology building. Every organization that has tried to manually maintain a knowledge graph of its systems has discovered the same thing: it's not a graph problem, it's a maintenance problem. The graph has to build itself from systems of record or it won't stay accurate long enough to be useful.
And they're treating governance as infrastructure, not process. The organizations that are getting this right aren't adding governance reviews on top of their agent workflows. They're building the context layer that makes governance a property of how the agent reasons, not a checkpoint it passes through. The OWASP risks for agentic applications are real. They're not solved by policy documents. They're solved by agents that can't make out-of-scope decisions because the graph makes scope verifiable at inference time.
The Foundation That Actually Makes Agents Work
There's a version of 2026 where most organizations look back on their first wave of agentic deployments and say: the models were fine, the tools were fine, we just didn't have the context infrastructure to make them reliable. And there's a version where the organizations that invested in that infrastructure early look back and say: we got two years of compounding advantage because we built the right foundation.
Live knowledge graphs aren't a nice-to-have layer on top of agentic AI. They're the substrate that makes agentic AI safe enough to run at scale, because they give agents something to reason over that's actually true about the organization right now, not six months ago.
As multi-agent orchestration becomes the enterprise control plane, the organizations that win won't be the ones with the most tools or the most capable models. They'll be the ones whose agents actually understand the organization they're operating in.
That understanding doesn't come from prompts. It doesn't come from document embeddings. It comes from a live graph.
Building agentic systems and hitting the context wall?
We're working with a small number of design partners. If your agents are hitting the context wall, let's talk.